Business Focused Data Vault
Rapid Iteration with Data Vault 2.0
Overview
As discussed in our earlier blog post, Data Vault 2.0 offers numerous advantages over more traditional approaches to Data Warehousing. Among the benefits discussed, the flexibility of Data Vault was highlighted as making the approach attractive to Agile development teams. In fact, Agile delivery is so baked into the Data Vault Methodology that an Agile work flow is considered the best practice when deploying Data Vault according to its creator, Dan Lindstedt’s book on Data Vault. Another advantage Data Vault offers over alternatives is its simplicity. At its core, Data Vault employs a simple set of rules for deploying objects into the warehouse. This simplicity paves the way for increased speed, repeatability, and automation.
Business Focused
The Data Vault Methodology puts the business front and center as they are the ones best positioned to know both the data and what their ultimate needs are. Delivering early and often using Agile practices allows the project to stay aligned with the end users’ needs and expectations throughout the process. Rather than developing and deploying each layer of the data warehouse in its entirety, the Data Vault Methodology encourages breaking the deployment into sprints (1-4 week iteration periods). Breaking the deployment into sprints allows the customer to take delivery at regular intervals and start reviewing artifacts for acceptance earlier than the end of the project.
Simplicity
The goal for each sprint is to deliver a testable, discrete feature to the customer for review. This includes the minimum footprint across all layers of the data warehouse: the complete source tables in the staging layer, raw vault tables to house the data in the warehouse layer, and views or tables to present the unified data in the information mart layer. Creation of these objects in turn is quite simple. In fact, the patterns at the heart of data vault model creation are representable in code — enabling scripts to manage creation of most objects.
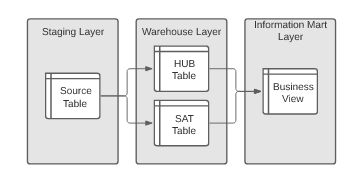
Using automation, file delivery can trigger creation and loading of a staging table to house the data. From there, scripts can run to create HUB, SAT, and LINK tables in the raw vault to house the staged data. From there, a script can run to generate views in an information mart to present the most recent point in time version of the data. With this automation in place delivery times can be reduced and delivery consistency can be increased, enabling more time and energy to be focused on delivering quality data products to the business.